Το κεφάλαιο αυτό παρέχει μια επισκόπηση των συστημάτων συστάσεων, των ωφελειών που προσφέρουν τόσο στην επιχείρηση όσο και στους πελάτες αυτής, και των προκλήσεων, οι οποίες αν αντιμετωπιστούν αποτελεσματικά, μπορούν να βελτιώσουν τη διαδικασία εξατομίκευσης και για τα δύο μέρη. Γίνεται επίσης μια περιγραφή των κύριων αλγόριθμων που χρησιμοποιούν τα συστήματα αυτά καθώς και του τρόπου αξιολόγησής τους. Συζητούνται δυο ενδιαφέρουσες πτυχές των συστημάτων συστάσεων: τα ζητήματα ιδιωτικότητας που προκύπτουν και οι τρόποι αξιοποίησης δεδομένων από κοινωνικά δίκτυα. Τέλος, γίνεται μια πρώτη διερεύνηση της εφαρμογής των συστημάτων συστάσεων σε κινητά περιβάλλοντα.
Προαπαιτούμενη γνώση
Το κεφάλαιο 1 του παρόντος συγγράμματος
1. Εισαγωγή στα συστήματα συστάσεων και εξατομίκευσης
Λόγω της ταχείας ανάπτυξης του Διαδικτύου σε συνδυασμό με το πρόβλημα της συσσώρευσης πληροφοριών, η χρήση των συστημάτων συστάσεων (recommender systems) έχει αρχίσει να γίνεται απαραίτητη και για τις ηλεκτρονικές επιχειρήσεις και για τους πελάτες. Ωστόσο, υπάρχουν και άλλοι παράγοντες, όπως η προστασία της ιδιωτικής ζωής και η εμπιστοσύνη που κάνουν τους πελάτες να μη θέλουν να χρησιμοποιήσουν αυτά τα συστήματα.
Η εξέλιξη των υπολογιστών σε συνδυασμό με την ταχεία ανάπτυξη των σχετικών υποδομών δικτύωσης έφερε το Ηλεκτρονικό Εμπόριο (ΗΕ) σε ένα νέο επίπεδο παροχής υπηρεσιών. Η χρήση του Διαδικτύου αυξάνει συνεχώς και η ανάγκη για το ΗΕ γίνεται όλο και πιο μεγάλη και με διαφορετικούς τρόπους (Jannach et al., 2010). Ωστόσο, δεδομένου ότι ο όγκος των πληροφοριών μεγαλώνει και οι άνθρωποι που χρησιμοποιούν τον Παγκόσμιο Ιστό (ΠΙ) γίνονται περισσότεροι, υπάρχει η ανάγκη για να αντιμετωπιστεί η πρόκληση της παροχής διαφορετικού περιεχομένου σε χρήστες με διαφορετικά ενδιαφέροντα. Η ανάγκη για να αντιμετωπιστεί η υπερφόρτωση πληροφοριών είναι ένα από τα πιο σημαντικά στις μέρες μας προβλήματα και οδηγεί στην αναγκαιότητα χρήσης των συστημάτων συστάσεων (Konstan & Riedl, 2012).
Τα συστήματα συστάσεων και εξατομίκευσης ασχολούνται με τη δυναμική προσαρμογή των δεδομένων που λαμβάνονται μέσω του ΠΙ και προσαρμόζονται με βάση τις προτιμήσεις του χρήστη (Shi et al., 2014; Ricci et al., 2011). Στόχος των συστάσεων μπορεί να είναι να βοηθήσουν τον χρήστη να αποφασίσει τι να αγοράσει, ποιόν να κάνει φίλο σε ένα κοινωνικό δίκτυο ή το τι να διαβάσει (Konstan & Riedl, 2012; Polatidis & Georgiadis, 2013; Prasad & Kumari, 2012). Λόγω του μεγάλου όγκου πληροφοριών στο Διαδίκτυο, η τεχνολογία εξατομίκευσης (personalization) αποτελεί ένα από τα πιο πολύτιμα εργαλεία στις μέρες μας. Θα πρέπει να σημειωθεί ότι πρόκειται για μια πολύ απαιτητική διαδικασία: η σχεδίαση και ανάπτυξη ενός τέτοιου συστήματος απαιτεί συνδυασμό γνώσεων και δεξιοτήτων από διαφορετικούς τομείς της επιστήμης των υπολογιστών (Konstan & Riedl, 2012; Ricci, 2011). Ένας αξιόλογος αριθμός αλγορίθμων έχει αναπτυχθεί τα τελευταία χρόνια, με τους περισσότερους να χρησιμοποιούνται σε εμπορικά περιβάλλοντα.
Επιπλέον, στον τομέα των κινητών συσκευών, το πρόβλημα πρόσβασης στην πληροφορία γίνεται ακόμη πιο δύσκολο λόγω των δυσκολιών που οφείλονται σε περιορισμούς του υλικού. Είναι σημαντικό να σημειωθεί ότι οι αλγόριθμοι που εφαρμόζονται σε συστήματα που βασίζονται στον ΠΙ δεν μπορούν να μεταφερθούν αυτούσια σε συστήματα που προορίζονται για μια κινητή συσκευή, αφού υπάρχουν διαφορετικές ανάγκες, χαρακτηριστικά και περιορισμοί.
Η ανάγκη για την προστασία της ιδιωτικής ζωής έχει γίνει μια πολύ σημαντική πτυχή των τεχνικών εξατομίκευσης (Kobsa, 2007; Shyong et al., 2006; Benats et al., 2011; Jeckmans et al., 2013). Είναι βέβαια ζωτικής σημασίας για το σύστημα το να χρησιμοποιηθούν κάποια ιδιωτικά δεδομένα προκειμένου να παραχθούν ακριβείς συστάσεις. Ωστόσο, θα πρέπει να ληφθεί υπόψη ότι η προστασία της ιδιωτικής ζωής είναι ένα τεράστιο ζήτημα των συστημάτων αυτών διότι η άρνηση των χρηστών να συμβάλλουν δίνοντας δεδομένα, καθιστά τα εξατομικευμένα περιβάλλοντα μη χρήσιμα (Jeckmans et al., 2013; Polatidis & Georgiadis, 2013). Το μεγαλύτερο μέρος των απλών χρηστών δε γνωρίζει πώς χρησιμοποιούνται τα δεδομένα αυτά και αντιδρούν με διάφορους τρόπους (Ricci, 2011).
Υπάρχουν ανοιχτά σχετικά ζητήματα που χρειάζονται εκτενή διερεύνηση, όπως οι επιχειρηματικές πτυχές των συστημάτων συστάσεων και ο περιορισμός του κόστους αναζήτησης. Επιπλέον θα πρέπει να διερευνηθούν και άλλοι παράμετροι όπως η επίγνωση θέσης και η αξιοποίηση γενικότερα της περιβάλλουσας κατάστασης (context) από τα συστήματα συστάσεων (Konstan & Riedl, 2012).
2. Η σημασία των συστημάτων συστάσεων για τις ηλεκτρονικές επιχειρήσεις
Τα συστήματα συστάσεων και εξατομίκευσης είναι αλγόριθμοι που χρησιμοποιούνται ευρέως στο ηλεκτρονικό εμπόριο για να προτείνονται προϊόντα ή υπηρεσίες σε χρήστες. Οι συστάσεις είναι για το τι αγορές να γίνουν, τι ανάγνωση ειδήσεων να γίνει, τι συνδέσεις κοινωνικής δικτύωσης να γίνουν και τι ταινίες να παρακολουθήσει ο χρήστης μεταξύ πολλών άλλων. Ανάμεσα στις πιο δημοφιλείς ιστοσελίδες που χρησιμοποιούν συστήματα συστάσεων είναι η Amazon.com, η οποία παρέχει μια εξατομικευμένη ιστοσελίδα για κάθε μεμονωμένο χρήστη. Το Netflix είναι ένα άλλο παράδειγμα ιστοσελίδας που χρησιμοποιεί εξατομικευμένα συστήματα για να προταθούν ταινίες και τηλεοπτικές εκπομπές. Τέτοια συστήματα γενικά δείχνουν μια λίστα με κορυφαία αντικείμενα που σχετίζονται με τον χρήστη. Τα στοιχεία που ανακτώνται είναι σύμφωνα με τους κανόνες που καθορίζονται από τον αλγόριθμο και προτείνονται ως κορυφαία από τη λίστα, ανάλογα με το περιβάλλον. Τα συστήματα συστάσεων αναπτύχθηκαν για να κάνουν τις καθημερινές αποφάσεις απλούστερες. Οι αποφάσεις αυτές είναι ως επί το πλείστον για υπηρεσίες χαμηλού κόστους, όπως τα βιβλία και οι προτάσεις ταινιών, με πρωταρχικό στόχο τη διευκόλυνση του χρήστη στη διαδικασία της αναζήτησης (Jannach et al., 2010; Ricci et al., 2011).
Αν και τα συστήματα συστάσεων και εξατομίκευσης αποτελούν ένα σχετικά νέο πεδίο μελέτης στη βιβλιογραφία, τεχνικές τους έχουν ευρέως υιοθετηθεί και έχουν λύσει καλά ως ένα βαθμό το πρόβλημα της υπερφόρτωσης πληροφοριών (Oulasvirta et al., 2012). Να σημειωθεί ότι η χρήση των συστημάτων συστάσεων είναι απαραίτητη για τους παρόχους υπηρεσιών και όχι μόνο για τους χρήστες (Polatidis & Georgiadis, 2013; Karimov & Brengman, 2011). Οι λόγοι για τους οποίους οι ηλεκτρονικές επιχειρήσεις χρησιμοποιούν τέτοια συστήματα είναι οι εξής (Polatidis & Georgiadis, 2013):
Ι. Αύξηση πωλήσεων
Ο πιο σημαντικός λόγος για να χρησιμοποιηθεί μια τεχνολογία συστάσεων είναι η αύξηση των πωλήσεων και των εσόδων του. Αυτό επιτυγχάνεται επειδή το σύστημα συστάσεων προτείνει συνήθως τα στοιχεία που είναι σχετικά με το χρήστη, σύμφωνα με το ιστορικό και τις προτιμήσεις του.
ΙΙ. Προώθηση ειδών που ανήκουν σε μία ευρύτερη γκάμα προϊόντων
Ένα σύστημα συστάσεων θα προτείνει συνήθως τα στοιχεία από μια μεγάλη ποικιλία προϊόντων που διαφορετικά ο χρήστης θα ήταν πολύ δύσκολο να εντοπίσει.
III. Αύξηση της ικανοποίησης των χρηστών
Ο χρήστης είναι περισσότερο ικανοποιημένος από τη συνολική υπηρεσία που προσφέρεται και είναι πιθανό να την προτείνει και σε άλλους.
IV. Αύξηση πίστης
Είναι πιο πιθανό για έναν χρήστη να επισκεφθεί ξανά μια ιστοσελίδα ή να ξανά χρησιμοποιήσει μια κινητή εφαρμογή, αν είναι ικανοποιημένος με την ποιότητα και γενικότερα την εμπειρία διάδρασης.
Σύμφωνα με τους Hinz & Eckert (2010) τα δύο πιο σημαντικά ζητήματα για μια ηλεκτρονική επιχείρηση που χρησιμοποιεί συστήματα συστάσεων είναι:
I. Μείωση του κόστους αναζήτησης
ΙΙ. Υψηλότερες πωλήσεις
Ως εκ τούτου είναι σαφές σε αυτό το στάδιο ότι οι επιχειρήσεις που θέλουν να είναι καινοτόμες, να αυξήσουν τις πωλήσεις τους και να είναι πιο αξιόπιστες για τον πελάτη, πρέπει να παρέχουν πιο εξατομικευμένες υπηρεσίες. Η εξατομίκευση του ίδιου του λειτουργικού συστήματος μπορεί να συνεισφέρει στην παραγωγή πιο κατάλληλων συστάσεων (Davidson & Livshits, 2012). Επιπλέον, οι κινητές συσκευές τείνουν να γίνουν η κύρια πηγή πρόσβασης σε κοινωνικά δίκτυα διότι υποστηρίζουν άμεση πρόσβαση από παντού στον ΠΙ (Jabeur et al., 2013; Oulasvirta et al., 2012).
Σε μια μελέτη τους οι Karimov & Brengman (2011) δείχνουν ότι τα συστήματα συστάσεων μπορούν να αποφέρουν σημαντικό κέρδος σε μια ηλεκτρονική επιχείρηση. Ωστόσο, οι ίδιοι ερευνητές διαπίστωσαν ότι μόνο το 1,4% των εσόδων των 210 κορυφαίων ιστοσελίδων οφείλεται στα συστήματα συστάσεων, διότι οι περισσότερες ιστοσελίδες δε χρησιμοποιούσαν κάποιο. Για να γίνει πιο αποτελεσματική η εξατομίκευση, πρέπει να δίνει τη δυνατότητα σε έναν ηλεκτρονικό πωλητή να αλληλοεπιδρά αυτόματα με τους πιθανούς πελάτες και να τους προσφέρει μια ποικιλία υπηρεσιών, αυξάνοντας την ικανοποίηση των πελατών (Riemer & Totz, 2001). Οι επιλογές που προσφέρονται από τα συστήματα συστάσεων πρέπει να προσαρμόζονται στις ανάγκες της κάθε επιχείρησης.
Η αξιοποίηση των μέσων κοινωνικής δικτύωσης είναι ένας σοβαρός παράγοντας επιτυχίας στις ηλεκτρονικές επιχειρήσεις. Οι κορυφαίες ιστοσελίδες προσπαθούν να αναπτύξουν μια κοινωνική παρουσία, με τη δημιουργία σελίδων σε δίκτυα όπως το Facebook και το Twitter. Αν και υπάρχουν αρκετές δυσκολίες, τα δεδομένα από τα κοινωνικά δίκτυα θα πρέπει να ενσωματώνονται σε συστήματα συστάσεων προκειμένου να βελτιώσουν τις συστάσεις, την ικανοποίηση των χρηστών και την εμπιστοσύνη σε ένα ηλεκτρονικό κατάστημα. Έχει καταγραφεί ότι όταν τα συστήματα συστάσεων χρησιμοποιούνται τότε η εμπιστοσύνη του πελάτη προς ένα ηλεκτρονικό κατάστημα είναι υψηλότερη (Qiu & Benbasat, 2009; Wang & Benbasat, 2007). Σε μια έρευνα τους οι Ochi et al. (2010) παρουσίασαν στοιχεία που δείχνουν ότι οι συστάσεις επηρεάζονται από τα δεδομένα των κοινωνικών δικτύων (χρησιμοποιείται τότε και ο όρος κοινωνικές συστάσεις).
3. Αλγόριθμοι συστημάτων συστάσεων και εξατομίκευσης
Ένα σύστημα συστάσεων παίρνει συνήθως ως είσοδο προσωπικές πληροφορίες από τον χρήστη, χρησιμοποιώντας έναν αλγόριθμο δημιουργεί τις συστάσεις, είτε τοπικά είτε σε ένα κατανεμημένο περιβάλλον και προσφέρει τις προβλέψεις στη διασύνδεση των υπηρεσιών που ο χρήστης χρησιμοποιεί. Οι δύο πιο σημαντικοί και ευρέως χρησιμοποιούμενοι αλγόριθμοι συστάσεων είναι οι εξής:
Συνεργατικό φιλτράρισμα (Collaborative filtering)
H βασική ιδέα είναι να βρούμε ποιοι χρήστες μοιράζονται τα ίδια ενδιαφέροντα με τον ενδιαφερόμενο χρήστη στο παρελθόν. Η κατηγορία αυτή των αλγορίθμων εξατομίκευσης στηρίζεται στο ότι οι χρήστες που έχουν παρόμοιες προτιμήσεις, βαθμολογούν και αξιολογούν με παρόμοιο τρόπο. Οι τεχνικές αυτές συνήθως λαμβάνουν ένα σύνολο με τις βαθμολογίες των χρηστών του συστήματος και παράγουν προβλέψεις σχετικά με το τι χρειάζεται ένας χρήστης, βασιζόμενες στους πιο κοντινούς (ως προς τις προτιμήσεις) σε αυτόν χρήστες (Jannach et al., 2010; Polatidis & Georgiadis, 2013).
Ο ακόλουθος πίνακας αντιπροσωπεύει μια βάση δεδομένων με αξιολογήσεις για την Αλίκη και τέσσερις άλλους χρήστες.
Users
Item1
Item2
Item3
Item4
Item5
Alice
5
3
4
4
Null
User1
3
1
2
3
3
User2
4
3
4
3
5
User3
3
3
1
5
4
User4
1
5
5
2
1
Πίνακας 4.1 Βάση δεδομένων με αξιολογήσεις
Ένας αριθμός μεθόδων ομοιότητας υφίστανται. Η μέθοδος ομοιότητας Pearson (Pearson correlation similarity) χρησιμοποιείται ευρέως. Μια άλλη μέθοδος ομοιότητας είναι η ομοιότητα συνημίτονου (Cosine similarity). Κάθε μέθοδος επιστρέφει έναν αριθμό από το -1 ως το 1. Όσο μεγαλύτερος είναι ο αριθμός αυτός τόσο μεγαλύτερη είναι η ομοιότητα ανάμεσα στους χρήστες. Η εικόνα 4.1 αποτυπώνει την ομοιότητα Pearson ενώ η εικόνα 4.2 αποτυπώνει την ομοιότητα συνημιτόνου.
Εικόνα 4.1 Pearson correlation similarity
Εικόνα 4.2 Cosine similarity
Κάντε κλικ στο παρακάτω πλαίσιο για την επεξήγηση των στοιχείων του παραπάνω τύπου:
Sim (a,b) είναι η ομοιότητα ανάμεσα στον χρήστη a και στον χρήστη b, r a,p είναι η βαθμολογία του χρήστη a για το προϊόν p, ενώ r b,p είναι η βαθμολογία του χρήστη b για το προϊόν p. Το P είναι το σύνολο των προϊόντων.
Φιλτράρισμα με βάση το περιεχόμενο (Content-based filtering)
Η εξατομίκευση με βάση το περιεχόμενο δε χρησιμοποιεί στοιχεία που αφορούν άλλους χρήστες πέραν του τρέχοντος χρήστη για τον οποίο παράγονται συστάσεις. Βασίζεται σε μεταδεδομένα (metadata) των πραγματικών δεδομένων, δηλαδή των προϊόντων/υπηρεσιών για τα οποία παράγονται συστάσεις. Αυτά μπορούν να είναι κάποια τεχνική περιγραφή, το είδος της ταινίας, ο τίτλος, τύπος, συγγραφέας ή άλλο καθορισμένο σύνολο των λέξεων-κλειδιών (Jannach et al., 2010). Ένας κατάλογος των ιδιοτήτων των προϊόντων/υπηρεσιών διατηρείται. Ο αλγόριθμος στηρίζει τη λειτουργία του με τον εντοπισμό προϊόντων/υπηρεσιών τα οποία έχουν ιδιότητες παρόμοιες με αυτές που ένας χρήστης προτίμησε στο παρελθόν. Είναι αποτελεσματικός σε συστήματα όπως πύλες ειδήσεων και καταστήματα βιβλίων, δηλαδή σε συστήματα που υπάρχει προφανής κατηγοριοποίηση των στοιχείων. Επιπλέον, η χρησιμότητά του γίνεται ακόμη μεγαλύτερη όταν δεν υπάρχουν αρκετές αξιολογήσεις για να εκτελεστεί αλγόριθμος κατηγορίας συνεργατικού φιλτραρίσματος.
Φιλτράρισμα με βάση τη γνώση (Knowledge-based filtering)
Σε ένα μέρος της βιβλιογραφίας, αναφέρεται ως διακριτή τρίτη κατηγορία το φιλτράρισμα με βάση τη γνώση. Τα συστήματα αυτά, βασίζονται σε δεδομένα που παρέχονται από τον χρήστη και χρησιμοποιούνται ως περιορισμοί, προκειμένου να του δοθούν συστάσεις.
Name
Price
Mega Pixels
Zoom
Screen size
Quality
Camera1
100
6
2x
2cm
Low
Camera2
119
8
2x
2.5cm
Medium
Camera3
200
12
4x
3cm
High
Camera4
150
10
3x
3cm
Medium
Camera5
140
8
4x
2.7cm
Medium
Πίνακας 4.2 Τεχνικά χαρακτηριστικά ψηφιακής κάμερας
Ο παραπάνω πίνακας περιγράφει τα χαρακτηριστικά ενός συνόλου
δεδομένων σχετικά με τις ψηφιακές φωτογραφικές μηχανές, όπως
διαπιστώθηκε στη βάση δεδομένων του συστήματος. Ο χρήστης μπορεί στη
συνέχεια να προσθέσει ένα σύνολο ειδικών κανόνων για το σύστημα
προκειμένου να λάβει συστάσεις.
Εξετάστε το ακόλουθο παράδειγμα που περιγράφεται με τη χρήση κανόνων
λογικής:
(Price <= 150) AND (MegaPixels >= 10) AND (Quality >= Medium)
Το σύστημα θα εμφανίσει όλες τις κάμερες με τις τιμές
τους να είναι μικρότερες ή ίσες με 150 και τα mega pixel τους
μεγαλύτερα από ή ίσο με 10 και η ποιότητά τους να είναι τουλάχιστον
μέση. Στην περίπτωση αυτή, η κάμερα νούμερο 4 θα εμφανιστεί διότι είναι
η μόνη που έχει τις προϋποθέσεις.
Υβριδικοί αλγόριθμοι
Ο υβριδισμός είναι ο συνδυασμός ή η χρήση στοιχείων από διαφορετικούς αλγόριθμους, προκειμένου να παραχθούν συστάσεις. Οι υβριδικοί αλγόριθμοι έχουν κατηγοριοποιηθεί σύμφωνα με τον σχεδιασμό τους (Jannach et al., 2010):
Monolithic
Ένας μονολιθικός αλγόριθμος ενσωματώνει διαφορετικά χαρακτηριστικά/παραμέτρους από διαφορετικούς αλγόριθμους. Θα μπορούσε να περιλαμβάνει κάθε χαρακτηριστικό που ένας αλγόριθμος υποστηρίζει ή έναν αριθμό από αυτά. Τα δεδομένα εισάγονται προς επεξεργασία υπό ένα κοινό σύνολο παραμέτρων και οι συστάσεις παρέχονται σε ένα κοινό σημείο εξόδου.
Parallelized
Ένα σύνολο τουλάχιστον δύο ή και παραπάνω αλγόριθμων τρέχει παράλληλα και στο τέλος οι συστάσεις ενσωματώνονται σε ένα κοινό σημείο εξόδου.
Pipelined
Ένας τέτοιος αλγόριθμος αποτελείται από δύο ή και παραπάνω αλγόριθμους. Κάθε αλγόριθμος τρέχει και οι συστάσεις που παρέχονται στο σημείο εξόδου χρησιμοποιούνται από τον επόμενο αλγόριθμο ως στοιχεία εισόδου, μέχρι τον τελευταίο.
4. Οφέλη ηλεκτρονικών επιχειρήσεων
Μελέτες έχουν δείξει ότι οι πελάτες εκτιμούν τα συστήματα συστάσεων και αισθάνονται πιο άνετα όταν επισκέπτονται μια ιστοσελίδα που είναι προσαρμοσμένη στις ανάγκες τους (ChoiceStream Personalization Survey, 2008). Αισθάνονται περισσότερη εμπιστοσύνη προς τον πωλητή και είναι πιθανό να τον επισκεφθούν ξανά και να κάνουν περισσότερες αγορές. Τα οφέλη για μία ηλεκτρονική επιχείρηση που χρησιμοποιεί εξατομικευμένα συστήματα είναι σημαντικά όταν συγκρίνονται με μη-εξατομικευμένες ιστοσελίδες, και είναι κυρίως οικονομικά. Υπάρχουν πράγματι πολλές μελέτες που δείχνουν ότι τα συστήματα συστάσεων είναι αρκετά κερδοφόρα για τις ηλεκτρονικές επιχειρήσεις (Wu et al., 2011; Cooperstain et al., 1999; Hinz & Eckert, 2010).
Σε ένα χαρακτηριστικό άρθρο του το CNN (Mangalindan, 2012) έχει συγκεντρώσει πληροφορίες για μία από τις πλέον σημαντικές ηλεκτρονικές επιχειρήσεις στον κόσμο, την Amazon, η οποία χρησιμοποιεί συστήματα συστάσεων και έχει να επιδείξει αύξηση στις συνολικές πωλήσεις της κατά 29% το 2011. Τα συστήματα συστάσεων μπορούν να μειώσουν το κόστος αναζήτησης για τις επιχειρήσεις, παρέχοντας στον χρήστη τα πιο κατάλληλα προϊόντα. Σύμφωνα με τους Wu et al. (2011), επειδή τα ηλεκτρονικά καταστήματα έχουν συνήθως μια μεγαλύτερη ποικιλία προϊόντων, τα συστήματα συστάσεων μπορούν να μειώσουν το κόστος των συναλλαγών με τη στόχευση προς τους χρήστες: προτείνουν οποιοδήποτε σχετικό προϊόν σε κάθε πελάτη, ο οποίος (ο ίδιος ή άλλοι πελάτες με ίδια ενδιαφέροντα με αυτόν) μπορεί να έχει δείξει προτίμηση σε παρόμοια προϊόντα. Σύμφωνα με την ίδια έρευνα, η σύσταση μπορεί να γίνει σε διάφορα στάδια της διαδικασίας πώλησης. Οι Fleder και Hosanager (2009) σε μελέτη τους έδειξαν ότι τα συστήματα συστάσεων μπορούν να αυξήσουν την πώληση των νέων προϊόντων προς τους πελάτες.
Οι Dias et al. (2008) έχουν δείξει μέσα από μία περίπτωση μελέτης 21 μηνών με πραγματικά δεδομένα ότι τα συστήματα συστάσεων όχι μόνο αυξάνουν τα οικονομικά οφέλη άμεσα, αλλά πάνε πολύ πέρα από αυτό. Υποστηρίζουν ότι υπάρχει άμεση σχέση των συστημάτων συστάσεων με τα επιπλέον έσοδα, τα οποία σχετίζονται με την αγορά ενός προϊόντος και έμμεσα επιπλέον έσοδα που σχετίζονται με την αγορά ενός προϊόντος που βρίσκεται στην ίδια κατηγορία με το προτεινόμενο προϊόν. Και επιχειρηματολογούν ότι η έμμεση αξία πωλήσεων παραμένει σταθερά υψηλότερη από την άμεση.
4.1 H προστασία της ιδιωτικής ζωής και η εμπιστοσύνη σε σχέση με τα οφέλη
Η μελέτη των Chellappa & Sin (2005) έδειξε ότι η εξατομίκευση είναι ένας πολύ σημαντικός παράγοντας για τους πελάτες όταν επισκέπτονται μια ιστοσελίδα και είναι πιθανό να κερδίσει την εμπιστοσύνη τους προς την κατεύθυνση του ηλεκτρονικού επιχειρείν. Τελικά, θα κάνουν περισσότερες αγορές και ως εκ τούτου το οικονομικό όφελος για τον πωλητή θα είναι υψηλότερο. Παράλληλα όμως, έρευνες σχετικά με την ιδιωτικότητα (privacy) έχουν δείξει ότι οι πελάτες θέλουν να ξέρουν πώς θα χρησιμοποιηθούν από την επιχείρηση τα στοιχεία που θα δώσουν (Kobsa & Teltzrow, 2005; Turow, 2003).
Ο Kobsa (2007) υπογραμμίζει ότι θα πρέπει να ληφθούν σοβαρά υπόψη οι νόμοι προστασίας της ιδιωτικής ζωής: η προστασία της ιδιωτικής ζωής είναι ζωτικής σημασίας για την εμπιστοσύνη, οπότε η παρουσία μίας δήλωσης προστασίας προσωπικών δεδομένων στο δικτυακό τόπο συναλλαγών κρίνεται απαραίτητη.
Ένας άλλος πολύ σημαντικός παράγοντας στη διαδικασία της δημιουργίας εμπιστοσύνης μεταξύ μιας ηλεκτρονικής επιχείρησης και ενός πελάτη είναι οι θετικές εμπειρίες. Μια μελέτη του Pavlou (2003) έχει δείξει ότι η εμπειρία παίζει ζωτικό ρόλο για την εμπιστοσύνη στις ιστοσελίδες. Ο σχεδιασμός και η λειτουργία ενός δικτυακού τόπου επηρεάζουν το κλίμα εμπιστοσύνης. Για να αυξηθεί η εμπιστοσύνη θα πρέπει να μειωθούν τα σφάλματα και η όλη διαδικασία της αγοράς να είναι εύχρηστη.
Άλλοι παράγοντες περιλαμβάνουν τη συνολική φήμη του δικτυακού τόπου (Schoenbachler & Gordon, 2002). Επίσης, ο Fogg (2002) αναφέρει ότι όσο περισσότερες είναι οι πληροφορίες σχετικά με την επιχείρηση τόσο μεγαλύτερη είναι η εμπιστοσύνη και ότι οι γρήγορες απαντήσεις σε διάφορα ερωτήματα δρουν θετικά. Τέλος, μια μελέτη του Turow (2003) έχει δείξει ότι οι οικονομικές ανταμοιβές για τους πελάτες μπορούν να αυξήσουν την εμπιστοσύνη τους και την πρόθεσή τους να εισάγουν περισσότερες ιδιωτικές πληροφορίες στην ιστοσελίδα
5. Περίπτωση μελέτης βασισμένη στην ηλεκτρονική επιχείρηση Amazon
Η Amazon είναι ένα από τα κορυφαία ηλεκτρονικά καταστήματα που έχει χρησιμοποιήσει συστήματα συστάσεων με επιτυχία για να αυξήσει τα οικονομικά οφέλη της. Παρέχει με διαφορετικό τρόπο συστάσεις σε διάφορα στάδια της διαδικασίας αγοράς. Όπως φαίνεται στην εικόνα 4.3 παρακάτω, εξατομικευμένες συστάσεις εμφανίζονται αφότου ο χρήστης έχει εισέλθει με επιτυχία στο Amazon και στο στάδιο αυτό παρέχονται συστάσεις σύμφωνα με προηγούμενες αγορές του. Οι υπολογισμοί γίνονται και προς τις δυο κατευθύνσεις: με βάση αλγορίθμους βασισμένους στο περιεχόμενο υπολογίζονται ομοιότητες ανάμεσα στα αντικείμενα που έχουν καταγραφεί στο ιστορικό του ως αγορές ή ακόμη και ως θετικές αξιολογήσεις και στα διαθέσιμα προς πώληση αντικείμενα. Και προτείνονται βέβαια τα πιο 'σχετικά'. Επίσης, υπολογισμοί γίνονται και με βάση αλγορίθμους συνεργατικού φιλτραρίσματος: υπολογίζονται ομοιότητες ανάμεσα στο προφίλ του χρήστη (δημογραφικά στοιχεία, ρητές δηλώσεις προτιμήσεων και καταγεγραμμένη στο δικτυακό τόπο συμπεριφορά/προτιμήσεις) με τα προφίλ άλλων καταγεγραμμένων χρηστών. Και προτείνονται οι πρόσφατες επιλογές των πιο ΄κοντινών' ως προς τις προτιμήσεις χρηστών. Υπάρχουν και γενικές συστάσεις, με βάση την έκπτωση και την εμπορική επιτυχία αντικειμένων (στη δεξιά πλευρά).
Εικόνα 4.3 Οι συστάσεις όπως εμφανίζονται στην αρχική σελίδα της Amazon
Η εικόνα 4.4 παρουσιάζει τις προσφερόμενες συστάσεις, αφού έκανε μια αγοραστική επιλογή ο χρήστης. Εμφανίζονται δύο διαφορετικοί τύποι συστάσεων: αντικείμενα που συχνά αγοράστηκαν μαζί με αυτό που μόλις επέλεξε ο χρήστης και τι άλλο έχουν αγοράσει άλλοι πελάτες που έχουν αγοράσει αυτό που επέλεξε ο χρήστης.
Εικόνα 4.4 Οι συστάσεις όπως εμφανίζονται κατά τη διάρκεια επιλογής προϊόντος
6. Προκλήσεις
Στις επόμενες παραγράφους θα συζητηθούν δυο ενδιαφέροντα θέματα της σχετικής βιβλιογραφίας των συστημάτων συστάσεων.
6.1 Ιδιωτικότητα
Οι χρήστες ανησυχούν για τα στοιχεία που χρειάζεται να προσφέρουν στα συστήματα συστάσεων. Για τον λόγο αυτό, αναπτύσσονται κατάλληλες πολιτικές προστασίας προσωπικών δεδομένων, που στοχεύουν να διασφαλίσουν ότι τα δεδομένα χρήστη θα παραμείνουν απολύτως ιδιωτικά. Χωρίς την πρόνοια αυτών, οι χρήστες τείνουν να παρουσιάζουν αρνητική συμπεριφορά, όταν τους ζητείται να εισάγουν τα δεδομένα τους προκειμένου να λάβουν πιο εξατομικευμένο περιεχόμενο (Shyong et al., 2006; Polatidis & Georgiadis, 2013; Jeckmans et al., 2013). Στα συστήματα συστάσεων, οι χρήστες χωρίζονται σε τρεις βασικές κατηγορίες, όσον αφορά τις αποφάσεις και τις επιλογές τους σχετικά με την ιδιωτικότητα (Shyong et al., 2006):
Ο χρήστης που θα δώσει κάθε είδους πληροφορία σε ένα σύστημα συστάσεων με αντάλλαγμα περισσότερο εξατομικευμένο περιεχόμενο.
Ο χρήστης που θα δώσει κάποιες πληροφορίες για ένα σύστημα συστάσεων, προκειμένου να πάρει βελτιωμένες προτάσεις.
Ο χρήστης που δε θα δώσει καμία πληροφορία σε ένα σύστημα συστάσεων, λόγω των ανησυχιών του για την ιδιωτικότητά του.
Η κατηγορία χρηστών που επιτρέπει εισαγωγή κάποιων πληροφοριών, περιορίζεται σε γενικά στοιχεία όπως το φύλο, η ηλικία και η εκπαίδευση. Αυτά τα δεδομένα δίνονται ευκολότερα σχετικά με περισσότερο συγκεκριμένα προσωπικά δεδομένα (Jeckmans et al., 2013). Ωστόσο, για να βελτιωθούν οι συστάσεις πρέπει να πεισθούν οι χρήστες να εισάγουν περισσότερα στοιχεία. Και αυτό σημαίνει να πεισθούν ότι τα δεδομένα τους θα είναι ασφαλή. Υπάρχουν διάφορες μέθοδοι διαφύλαξης της ιδιωτικότητας στα συστήματα συστάσεων, που στηρίζονται σε τεχνικές εξόρυξης δεδομένων Ιστού (Web mining) και στις οποίες θα αναφερθούμε σε επόμενο κεφάλαιο, εστιάζοντας στα κινητά συστήματα συστάσεων.
Σε ορισμένες πάντως περιπτώσεις, η διεξαγωγή έρευνας σχετικά με τις ανησυχίες ιδιωτικότητας των τρεχόντων χρηστών, βοηθά στη διερεύνηση των λύσεων που θα ακολουθηθούν. Η έρευνα αυτή μπορεί να γίνει είτε σε ένα εργαστήριο, χρησιμοποιώντας τεχνικές παρατήρησης, είτε σε πραγματικό περιβάλλον, ζητώντας από τους χρήστες να απαντήσουν σε κατάλληλες ερωτήσεις. Επίσης, βοηθά στην 'διασκέδαση' των όποιων ανησυχιών, το να καταστούν απολύτως σαφή προς τους χρήστες τα οφέλη της εξατομίκευσης, και βεβαίως η παροχή μιας πολύ σαφούς, πιστοποιημένης, δήλωσης προστασίας προσωπικών δεδομένων. Οι χρήστες θέλουν να είναι σίγουροι για τον τρόπο χρήσης των δεδομένων τους.
6.2 Ενσωμάτωση δεδομένων από κοινωνικά δίκτυα
Η ενσωμάτωση των κοινωνικών δικτύων στα κινητά λειτουργικά συστήματα, σε συνδυασμό με την ανάπτυξη και την ταχύτητα του Internet έχει οδηγήσει στην παραγωγή τεράστιων ποσοτήτων δεδομένων κοινωνικής δικτύωσης. Για τις επιχειρήσεις είναι ένας από τους ευκολότερους τρόπους συλλογής δεδομένων: οι χρήστες είναι πρόθυμοι να μοιραστούν απόψεις, αξιολογήσεις κλπ. Ωστόσο, η επιλογή και ο διαχωρισμός των χρήσιμων στοιχείων για τα συστήματα εξατομίκευσης και γενικότερα για τη βελτίωση των διαδικασιών ΗΕ, είναι μια διαδικασία γεμάτη προκλήσεις. Τα δεδομένα από τα κοινωνικά δίκτυα θα πρέπει να μπορούν να χρησιμοποιηθούν αποτελεσματικά για να βοηθηθούν τελικά οι πελάτες μέσω της παραγωγής πιο εύστοχων συστάσεων προς αυτούς.
Ένα τεράστιο ποσό δεδομένων δημιουργείται στα κοινωνικά δίκτυα καθημερινά και αυτό είναι μια τάση που αυξάνεται με γεωμετρική πρόοδο. Ως ενδεικτικό ποσοστό, ας αναφέρουμε ότι ο αριθμός των χρηστών Facebook και Twitter αυξήθηκε κατά 112% και 347% αντίστοιχα την περίοδο Ιανουάριος 2009 - Ιανουάριος 2010 (Jabeur et al., 2013). Ωστόσο, έχουν αναφερθεί και ζητήματα ποιότητας των στοιχείων: υπάρχει ένας αριθμός κακόβουλων χρηστών που δημιουργούν δεδομένα και αλλοιώνονται έτσι τα στοιχεία των πραγματικών χρηστών (Gundecha et al., 2012).
Τα κοινωνικά δίκτυα προσφέρουν διεπαφές προγραμματισμού εφαρμογών (APIs) που μπορούν να χρησιμοποιηθούν για την επικοινωνία μαζί τους, και την εξόρυξη πληροφοριών χρήσης τους. Εκτός από τις πληροφορίες που σχετίζονται με τον χρήστη (όπως φύλο, ηλικία, υπόβαθρο, κατάσταση σχέσης), υπάρχει ένας αριθμός (πολύ χρήσιμων για την εξατομίκευση) δυναμικών στοιχείων που μεταβάλλεται συνεχώς. Σε αυτό το δυναμικό περιεχόμενο περιλαμβάνονται ενδεικτικά η διάθεση, η τοποθεσία, οι θέσεις και τα μηνύματα που στάλθηκαν από άλλους χρήστες (Liu & Maes, 2004). Κάνοντας όμως σύνδεση και με τα ζητήματα ιδιωτικότητας της προηγούμενης παραγράφου, απαιτείται η ανάκτηση των δεδομένων από τα κοινωνικά δίκτυα να γίνεται χωρίς τη διακύβευση της ιδιωτικής ζωής των χρηστών.
7. Αξιολόγηση των συστημάτων συστάσεων
Η
αξιολόγηση συστημάτων συστάσεων και οι αλγόριθμοι τους είναι εγγενώς
δύσκολο να αξιολογηθούν για διάφορους λόγους (Herlocker at al., 2004):
Διαφορετικοί αλγόριθμοι μπορεί να είναι καλύτεροι ή χειρότεροι για διαφορετικά σύνολα δεδομένων (data sets).
Ένας αριθμός αλγόριθμων έχει σχεδιαστεί ειδικά για σύνολα
δεδομένων όπου ο αριθμός των χρηστών είναι περισσότερος από τον αριθμό των
προϊόντων. Αυτοί οι αλγόριθμοι δεν αποδίδουν το μέγιστο όταν τα
προϊόντα είναι περισσότερα από τους χρήστες.
Η αξιολόγηση είναι δύσκολη όταν οι στόχοι για τους οποίους γίνεται η αξιολόγηση διαφέρουν.
Οι
περισσότεροι αλγόριθμοι έχουν επικεντρωθεί στην ποιότητα (accuracy) των
συστάσεων, ενώ θα έπρεπε να ληφθούν υπόψιν και άλλοι παράγοντες όπως
π.χ. το τι τελικά αγοράζει ο χρήστης.
Μία πρόκληση είναι
το τι μονάδα μέτρησης θα χρησιμοποιηθεί για να αξιολογηθεί ένας
αλγόριθμος, αλλά και το γεγονός ότι οι ίδιοι χρήστες δίνουν
διαφορετικές βαθμολογίες (ratings) σε διαφορετικούς χρόνους.
Για να αξιολογηθεί σωστά ένα σύστημα συστάσεων, είναι σημαντικό να κατανοήσουμε τους στόχους και τα καθήκοντα για τα οποία χρησιμοποιείται. Η επιλογή των συνόλων δεδομένων που θα χρησιμοποιηθούν επηρεάζει την επιτυχή αξιολόγηση του αλγόριθμου συστάσεων. Ακόμη, μπορεί η αξιολόγηση να πραγματοποιηθεί χωρίς σύνδεση στο Διαδίκτυο χρησιμοποιώντας έτοιμα σύνολα δεδομένων ή να απαιτεί δοκιμές χρηστών σε online περιβάλλοντα. Εάν ένα σύνολο δεδομένων δεν είναι επί του παρόντος διαθέσιμο, μπορεί η αξιολόγηση να πραγματοποιηθεί σε προσομοιωμένα, συνθετικά σύνολα δεδομένων (synthetic data sets).
Για παράδειγμα, όταν σχεδιάζουμε έναν αλγόριθμο ο οποίος προορίζεται για τη σύσταση ταινιών, το πιο πιθανό είναι ότι δε θα προσφέρει ικανοποιητικά αποτελέσματα σε άλλα δεδομένα. Ή όταν θέλουμε να φτιάξουμε έναν αλγόριθμο που θα συστήνει νέα, καινοτόμα, προϊόντα τότε ένα σύνολο δεδομένων για offline αξιολόγηση δεν είναι αρκετό. Επίσης, όταν αξιολογούμε έναν αλγόριθμο σε ένα νέο περιβάλλον όπου δεν υπάρχουν έτοιμα σύνολα δεδομένων, τότε μπορούμε να δημιουργήσουμε συνθετικά σύνολα δεδομένων. Ο πίνακας 4.3 μας δίνει μία λίστα με τα πιο γνωστά σύνολα δεδομένων και τα χαρακτηριστικά τους. Ενώ ο πίνακας 4.4 μας δίνει μία όψη αξιολογήσεων ενός χρήστη σε μία βάση δεδομένων.
Όνομα
Πεδίο
Χρήστες
Προϊόντα
Αξιολογήσεις
BX
Βιβλία
278,858
271,379
1,149,780
EachMovie
Ταινίες
72,916
1,628
2,811,983
Entrée
Εστιατόρια
50,672
4,160
Δεν υπάρχουν
Epinions
Εμπόριο
49,000
140,000
665 ΧΙΛ
Jester
Ανέκδοτα
73,421
101
4,1 ΕΚ.
MovieLens 100k
Ταινίες
967
4,700
100 ΧΙΛ.
MovieLens 1m
Ταινίες
6,040
3,900
1 ΕΚ.
MovieLens 10m
Ταινίες
71,657
10,681
10 ΕΚ.
Netflix
Ταινίες
480,000
18,000
100 ΕΚ.
Ta-Feng
Εμπόριο
32,266
Μη διαθέσιμο
800 ΧΙΛ.
Πίνακας 4.3 Σύνολα δεδομένων
Στήλη
ID του χρήστη
ID προϊόντος
Βαθμολογία
1
1
200
3
2
1
150
5
3
1
100
5
4
1
102
2
5
1
3
3
6
1
99
4
7
1
399
1
8
1
408
5
9
1
1
2
10
1
11
3
Πίνακας 4.4 Αξιολογήσεις προϊόντων
Χρησιμοποιώντας ένα σύνολο δεδομένων όπως ένα από αυτά που αναφέρονται στον πίνακα 4.3 θα μπορέσουμε να διαπιστώσουμε πόσο καλός είναι ο αλγόριθμος μας. Ένα ολοκληρωμένο σύνολο δεδομένων αποτελείται από έναν αριθμό χρηστών που έχουν βαθμολογήσει κάποια προϊόντα (στη μορφή των εγγραφών του πίνακα 4.4, υπάρχουν εκτός του χρήστη 1 και πολλοί άλλοι χρήστες με τις βαθμολογίες τους).
Το επόμενο βήμα είναι να χρησιμοποιηθεί μία μονάδα μέτρησης ακρίβειας (accuracy metric) για να διαπιστωθεί το πόσο καλός είναι ο αλγόριθμος. Οι πιο διαδεδομένες μονάδες μέτρησης είναι το Mean Absolute Error (MAE) και το Root Mean Square Error (RMSE) (Jannach et al., 2010). Επίσης χρησιμοποιούνται και οι μονάδες μέτρησης Precision και Recall που προέρχονται από τα παραδοσιακά συστήματα εξόρυξης δεδομένων. Η εικόνα 4.5 δείχνει την έκφραση της μονάδας μέτρησης MAE. Η εικόνα 4.6 δείχνει την έκφραση της μονάδας μέτρησης RMSE. Οι εικόνες 4.7 και 4.8 δείχνουν τις εκφράσεις των μετρικών Precision και το Recall αντίστοιχα.
Η μονάδα μέτρησης MAE υπολογίζει την απόκλιση (deviation) ανάμεσα στις υπάρχουσες βαθμολογίες και στις υπολογισμένες από τον αλγόριθμο. Στους τύπους των εικόνων 4.5 και 4.6, το pi εκφράζει την υπολογισμένη βαθμολογία ενώ το ri εκφράζει την υπάρχουσα βαθμολογία που έχει δώσει ο χρήστης. Επίσης η μονάδα RMSE είναι παρόμοια με τη ΜΑΕ αλλά δίνει μεγαλύτερο βάρος στη μεγαλύτερη απόκλιση. Στις μονάδες μέτρησης ΜΑΕ και RMSE οι μικρότερες μετρήσεις είναι οι καλύτερες.
Εικόνα 4.5 Mean Absolute Error
Εικόνα 4.6 Root Mean Square Error
Η μονάδα μέτρησης Ακρίβεια (Precision) μετράει το ποσοστό των συστάσεων που ορθά προτάθηκαν από τον αλγόριθμο (True Positive) σε σχέση με το σύνολο των συστάσεων. Το μεγαλύτερο ποσοστό είναι το καλύτερο. Η Ακρίβεια ορίζεται λοιπόν ως ο λόγος των ορθών συστάσεων προς το σύνολο των συστάσεων, ορθών και λανθασμένων που παρήγαγε ο αλγόριθμος (True Positive + False Positive).
Η μονάδα μέτρησης Ανάκληση (Recall) μετράει το ποσοστό των συστάσεων που ορθά προτάθηκαν από τον αλγόριθμο (True Positive) σε σχέση με το (ιδανικό) σύνολο όλων των συστάσεων που θα μπορούσαν να προταθούν. Η Ανάκληση ορίζεται λοιπόν ως ένας λόγος που ο αριθμητής της είναι ίδιος με την Ακρίβεια (είναι και πάλι το πλήθος True Positive), αλλά διαφέρει στον παρονομαστή, όπου έχει το σύνολο των συστάσεων που προτάθηκαν ορθά και αυτών που λανθασμένα δεν προτάθηκαν (True Positive + False Negative). Επίσης οι μεγαλύτερες τιμές στην Ανάκληση, είναι οι καλύτερες.
Στις παρακάτω εικόνες υπάρχουν και δυο εναλλακτικές εκφράσεις των μετρικών αυτών, στις οποίες το σύνολο (True Positive + False Positive) αντιστοιχεί στο πλήθος των retrieved recommendations, δηλαδή των συστάσεων που παρήγαγε ο αλγόριθμος, ενώ το σύνολο (True Positive + False Negative) αντιστοιχεί στο πλήθος των relevant recommendations, δηλαδή των συστάσεων που θα έπρεπε να δοθούν. Με το ακόλουθο, απλοϊκό ως ένα βαθμό, παράδειγμα, θα γίνει κατανοητή η διαφορά ανάμεσα στις δυο αυτές μετρικές: έστω ότι ο αλγόριθμος παρήγαγε 3 συστάσεις (retrieved recommendations), τις α, β και γ, ενώ ο χρήστης τελικά ως ενέργειες ακολούθησε 4 ενέργειες (relevant recommendations), τις α, β, δ και ε. Έχουμε λοιπόν στα δυο σύνολα, δυο μόνο κοινά στοιχεία, τα α και β, οπότε η True Positive έχει τιμή 2. Η τιμή της Precision είναι 2/3, δηλαδή περίπου 67%. Η τιμή της Recall αντίστοιχα είναι 2/4, δηλαδή 50%. Η σύσταση γ προτάθηκε λανθασμένα, οπότε η τιμή της False Positive είναι 1. Οι ενέργειες δ και ε δεν προτάθηκαν από τον αλγόριθμο, οπότε η τιμή της False Negative είναι 2.
Εικόνα 4.7 Precision
Εικόνα 4.8 Recall
Στην εικόνα 4.9 μπορούμε να δούμε μία σύγκριση τριών αλγόριθμων τύπου συνεργατικού φιλτραρίσματος (χρήση μετρικής MAE), στους οποίους για τα ζητήματα ομοιότητας μεταξύ χρηστών χρησιμοποιήθηκε η τιμή 20, δηλαδή ορίσθηκε όπως λέγεται γειτονιά 20 χρηστών. Η μικρότερη τιμή είναι η καλύτερη. Στην εικόνα 4.10 μπορούμε να δούμε άλλη σύγκριση των τριών αλγόριθμων (θα μιλήσουμε σε λίγο για αυτούς), με χρήση της μετρικής RMSE και γειτονιάς 5 χρηστών. Η μικρότερη τιμή είναι η καλύτερη και εδώ. Και στις δύο περιπτώσεις το σύνολο των πιο κοντινών χρηστών (neighborhood) έχει οριστεί από πριν έτσι ώστε να μπορέσουν να γίνουν οι υπολογισμοί. Θα πρέπει να επισημανθεί επίσης ότι για τις μετρήσεις χρησιμοποιήθηκε το Epinions dataset.
Εικόνα 4.9 Παράδειγμα μέτρησης ΜΑΕ
Εικόνα 4.10 Παράδειγμα μέτρησης RMSE
Ένας παράγοντας που θα πρέπει να οριστεί στο προγραμματιστικό περιβάλλον για να γίνουν οι μετρήσεις είναι το ποσοστό του συνόλου που θα χρησιμοποιηθεί για το τεστ. Δηλαδή αν υποθέσουμε ότι το σύνολο των χρηστών του συνόλου δεδομένων που χρησιμοποιούμε ορίζεται με μία μεταβλητή Χ η οποία έχει τιμή 1.0 (100%) θα πρέπει να σπάσουμε αυτή την τιμή σε ένα σύνολο εκπαίδευσης (training test) που θα μπορούσε να είναι πχ. 0.30 (30%) ή 0.70 (70%) και το υπόλοιπο ποσοστό προορίζεται για να γίνουν οι μετρήσεις. Αυτό ισχύει για όλες τις μονάδες μέτρησης (MAE, RMSE, Precision, Recall). Σημαντική παράμετρος βέβαια είναι η μονάδα μέτρησης ομοιότητας (similarity) πχ. Pearson ή Cosine. Θα ήταν χρήσιμο να αναφερθούν επίσης εδώ, οι βιβλιοθήκες/APIs LensKit και Apache Mahout που μπορούν να χρησιμοποιηθούν σε περιβάλλον Java για να γίνουν δοκιμές και μετρήσεις επί προσεγγίσεων συστάσεων.
Όπου D1 ως Dnείναι οι διαστάσεις (n πλήθους)που περιλαμβάνουν το Uτο Iαλλά και άλλους παράγοντες όπως η
τοποθεσία, η ώρα κλπ. Για παράδειγμα θα μπορούσε η
συνάρτηση να είναι ως εξής (Εικόνα 4.15):
Εικόνα 4.15 Συμβολισμός τριών διαστάσεων για τη συνάρτηση παραγωγής συστάσεων
Είναι συνάρτηση τριών διαστάσεων: περιλαμβάνει τον χρήστη, το στοιχείο και την τοποθεσία (δηλαδή ο χρήστης είναι το D1, το προϊόν το D2 και η τοποθεσία το D3).
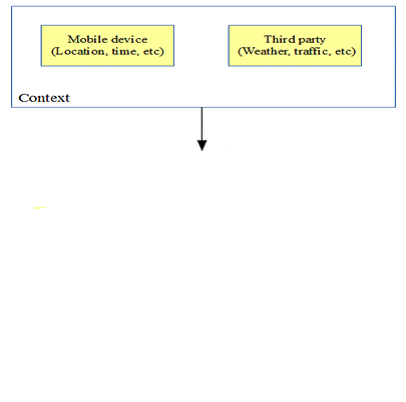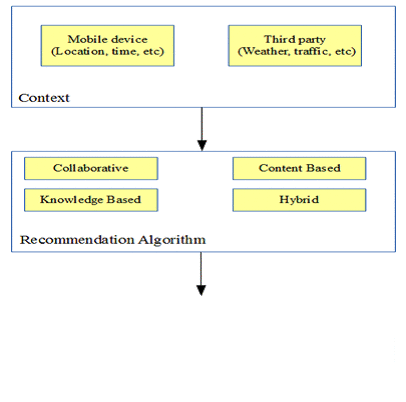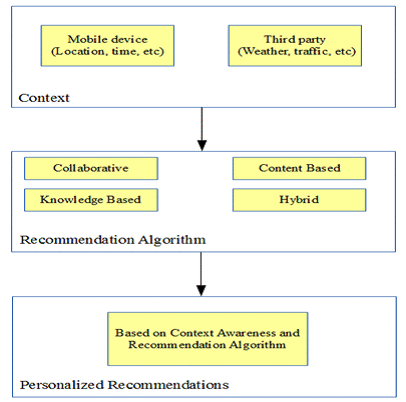
Η εικόνα 4.16 οπτικοποιεί, σε ένα αφαιρετικό επίπεδο, ένα σύστημα συστάσεων που χρησιμοποιεί πληροφορίες πλαισίου. Τέλος, στον πίνακα 4.5 αναγράφονται συνοπτικά οι διαφορές ανάμεσα στα παραδοσιακά συστήματα συστάσεων και σε αυτά που λειτουργούν σε κινητά περιβάλλοντα. Να σημειώσουμε εδώ ότι μεγαλύτερη ανάλυση του κινητού περιβάλλοντος θα γίνει σε επόμενο κεφάλαιο. Με βάση την ανάλυση αυτή, θα 'επισκεφθούμε' ξανά τα κινητά συστήματα συστάσεων για να συζητήσουμε τις ιδιαιτερότητές τους.
Κάντε κλικ για επαναληψη της κινησης στην παρακάτω εικόνα:
Σχήμα 4.16 Σύστημα
συστάσεων βασισμένο στην περιβάλλουσα κατάσταση
Πρόκληση
Διαδικτυακά συστήματα
Κινητά συστήματα
Θέματα ενέργειας
OXI
ΝΑΙ
Μέγεθος αποθηκευτικής μνήμης
OXI
ΝΑΙ
Ασύρματη σύνδεση στο Διαδίκτυο
OXI
ΝΑΙ
Άλλα θέματα συνδεσιμότητας
OXI
ΝΑΙ
Διεπαφή με τον χρήστη
ΝΑΙ
ΝΑΙ
Λειτουργία χωρίς φυσική παρουσία χρήστη
OXI
ΝΑΙ
Φιλικό περιβάλλον προς τον μέσο χρήστη
ΝΑΙ
ΝΑΙ
Μπορεί να βελτιωθεί η εμπειρία του χρήστη
ΝΑΙ
ΝΑΙ
Μπορεί να βελτιωθεί η αλληλεπίδραση
ΝΑΙ
ΝΑΙ
Να μαντέψει την πρόθεση του χρήση
ΝΑΙ
ΝΑΙ
Μικρότερο μέγεθος εισαγωγής δεδομένων
OXI
ΝΑΙ
Δύσχρηστο
ΝΑΙ
ΝΑΙ
Θέματα ιδιωτικότητας
ΝΑΙ
ΝΑΙ
Πρόβλημα νέου χρήστη
ΝΑΙ
ΝΑΙ
Πρόβλημα νέου προϊόντος
ΝΑΙ
ΝΑΙ
Οι χρήστες ξοδεύουν λιγότερο χρόνο
OXI
ΝΑΙ
Πίνακας 4.5 Σύγκριση διαδικτυακών και κινητών συστημάτων συστάσεων
9. Συμπεράσματα
Η εξατομίκευση είναι μια τεχνολογία που επιτρέπει τις δυναμικές προσαρμογές στην παρεχόμενη πληροφορία, υπηρεσία ή προϊόν. Οι προσαρμογές βασίζονται στις προτιμήσεις ενός χρήστη (ή κάποιας προγενέστερης στάσης αυτού), στις προτιμήσεις άλλων χρηστών, αλλά και σε παραμέτρους της περιβάλλουσας κατάστασης. Στόχος, να παρέχει στους χρήστες ό,τι τους ταιριάζει περισσότερο και όπως το προτιμούν, αντί της παροχής του ίδιου περιεχομένου στο ίδιο ύφος. Η παροχή συστάσεων και εξατομικευμένων πληροφοριών είναι ένας κρίσιμος παράγοντας σχετικά με την αποτελεσματικότητα ενός δικτυακού τόπου συναλλαγών: έχοντας τη δυνατότητα να 'κατανοήσει' τις ανάγκες του κάθε χρήστη, προσαρμόζει τους πόρους του για να ανταποκριθεί καλύτερα στις ανάγκες του. Το κεφάλαιο αυτό περιγράφει τα συστήματα συστάσεων, τους κυριότερους αλγορίθμους αυτών, καθώς και τα οφέλη που τόσο η επιχείρηση όσο και οι πελάτες έχουν. Ιδιαίτερη σημασία δίνεται στις προκλήσεις που τα σύγχρονα συστήματα συστάσεων καλούνται να αντιμετωπίσουν: στη διαφύλαξη της ιδιωτικότητας των χρηστών και στην εύρεση κατάλληλων τρόπων αξιοποίησης των δεδομένων που συλλέγονται στον ΠΙ μέσω των κοινωνικών δικτύων. Ο χώρος των κινητών συστημάτων συστάσεων, με το ακόμη πιο σύνθετο αλλά και πλούσιο πλαίσιο παραμέτρων που προσφέρει η κινητή συσκευή, είναι πολύ ενδιαφέρουσα περιοχή μελέτης, και μια πρώτη διερεύνηση των σχετικών θεμάτων γίνεται σε αυτό το κεφάλαιο επίσης. Περαιτέρω ανάλυση για τα συστήματα συστάσεων σε κινητές συσκευές και τα σχετικά ζητήματα ασφάλειας-ιδιωτικότητας θα γίνει στο κεφάλαιο 7.
10. Τεστ αξιολόγησης
Σημείωση: Η διαβάθμιση δυσκολίας των κριτηρίων αξιολόγησης δίνεται με το πλήθος των αναγραφόμενων αστερίσκων.
11. Βιβλιογραφία
Adomavicius, G., Sankaranarayanan, R., Sen, S. & Tuzhilin, A. (2005). Incorporating contextual information in recommender systems using a multidimensional approach. ACM Transactions on Information Systems (TOIS), 23(1), 103-145.
Benats, G., Bandara, A., Yu, Y., Colin, J.-N. & Nuseibeh, B. (2011). PrimAndroid: privacy policy modelling and analysis for Android applications. In: IEEE International Symposium on Policies for Distributed Systems and Networks (POLICY 2011) (pp. 129-132). Washington, DC: IEEE.
Chellappa, R. K. & Sin, R. G. (2005). Personalization versus Privacy: An Empirical Examination of the Online Consumer's Dilemma. Information Technology and Management, 6(2-3), 181-202.
ChoiceStream Personalization Survey: Consumer Trends and Perceptions (2008). Retrieved October 21 2013 from: http://www.choicestream.com/pdf/ChoiceStream_ 2008_Personalization_Survey.pdf
Cooperstain, D., Delhagen, K., Aber. A. & Levin, K. (1999). Making Net Shoppers Loyal. Forrester Research, Cambridge, MA.
Davidson, D. & Livshits, B. (2012). MoRePriv: Mobile OS Support for Application Personalization and Privacy. TechReport, Microsoft Research, Redmond, WA 98052, United States.
Fleder, D. M. & Hosanagar, K. (2009). Blockbuster Culture's Next Rise or Fall: The Impact of Recommender Systems on Sales Diversity. Management Science, 55(5), 697-712.
Fogg, B. J. (2002). Persuasive Technology: Using Computers to Change what We Think and Do. Ubiquity. December (2002): 5
Gundecha, P., & Liu, H. (2012). Mining Social Media: A Brief Introduction. Tutorials in Operations Research.
Herlocker, J. L., Konstan, J. A., Terveen, L. G. & Riedl, J. T. (2004). Evaluating collaborative filtering recommender systems. ACM Transactions on Information Systems (TOIS), 22(1), 5-53.
Hinz, O. & Eckert, J. (2010). The Impact of Search and Recommendation Systems on Sales in Electronic Commerce. Business & Information Systems Engineering, 2(2), 67-77.
Jabeur, N., Zeadally, S. & Sayed, B. (2013). Mobile social networking applications. Communications of the ACM, 56(3), 71-79.
Jannach, D., Zanker, M., Felfernig, A. & Friedrich, G. (2010). Recommender Systems: An Introduction, Cambridge University Press.
Jeckmans, A., Beye, M., Erkin, Z., Hartel, P., Lagendijk, R. & Tang, Q. (2013) Privacy in recommender systems. In: Social media retrieval. Computer Communications and Networks. Springer Verlag, London, 263-281.
Karimov, F. P. & Brengman, M. (2011). Adoption of Social Media by Online Retailers: Assessment of Current Practices and Future Directions. International Journal of E-Entrepreneurship and Innovation, 2(1), 26-45.
Kobsa, A. (2007) Privacy-Enhanced Web Personalization. The Adaptive Web, LNCS 4321, 628-670.
Kobsa, A. & Teltzrow, M. (2005). Contextualized Communication of Privacy Practices and Personalization Benefits: Impacts on Users' Data Sharing and Purchase Behavior. In D. Martin & A. Serjantov, Privacy Enhancing Technologies, 4th International Workshop, Toronto, Canada (PET 2004) Revised Selected Papers (pp. 329—343).
Konstan, J. Riedl, J. (2012). Recommender systems: from algorithms to user experience. User Modeling and User-Adapted Interaction, 22(1-2), 101-123.
Liu, H. & Maes, P. (2004). InterestMap: Harvesting Social Network Profiles for Recommendations. Beyond Personalisation-IUI, December:56.
Mangalindan, J. P. (2012). Amazon's Recommendations secrets. Retrieved October 21 2013 from: http://tech.fortune.cnn.com/2012/07/30/amazon-5/.
Ochi, P., Rao, S., Takayama, L. & Nass, C. (2010). Predictors of user perceptions of web recommender systems: How the basis for generating experience and search product recommendations affects user responses. International Journal of Human Computer Studies, 68(8), 472-482.
Oulasvirta, A., Rattenbury, T., Ma, L. & Raita, E. (2012). Habits make smartphone use more pervasive. Personal and Ubiquitous Computing, 16(1), 105-114.
Pavlou, P. A. (2003). Consumer Acceptance of Electronic Commerce: Integrating Trust and Risk with the Technology Acceptance Model. International Journal of Electronic Commerce 7(3), 101-134.
Polatidis, N. & Georgiadis, C. K. (2013). Mobile Recommender Systems: An Overview of Technologies and Challenges. In: IEEE Proceedings of the Second International Conference on Informatics and Applications (ICIA 2013) (pp. 282-287) Washington, DC: IEEE.
Prasad, R. & Kumari, V. V. (2012). A Catagorical Review of Recommender Systems. International Journal of Distributed and Parallel Systems (IJDPS) 3(5), 73-83.
Qiu, L. & Benbasat, I. (2009). Evaluating Anthropomorphic Product Recommendation Agents: A Social Relationship Perspective to Designing Information Systems. Journal of Management Information Systems, 25(4), 145-182.
Ricci, F., Rokach, L., Shapira, B. & Kantor, P. (2011). Recommender systems handbook, Springer.
Ricci, F. (2011). Mobile Recommender Systems. International Journal of Information Technology and Tourism. 12(3), 205-231.
Riemer, K. & Totz, C. (2001). The many faces of personalization – An Integrated economic overview of mass customization and personalization. In Proceedings of the World Congress of Mass Customization and Personalization (MCPC 2001).
Schoenbachler, D. D. & Gordon, G. L. (2002). Trust and customer willingness to provide information in database-driven relationship marketing. Journal of Interactive Marketing, 16(3), 2-16.
Shi, Y., Larson, M. & Hanjalic, A. (2014). Collaborative filtering beyond the user-item matrix: A survey of the state of the art and future challenges. ACM Computing Surveys (CSUR) 47.1: 3.
Shyong, K., Lam, T., Frankowski, D. & Riedl, J. (2006). Do you trust your recommendations? An exploration of security and privacy issues in recommender systems. In Proceedings of the International Conference on Emerging Trends in Information and Communication Security (ETRICS), LNCS 3995. 14-29.
Turow, J. (2003) Americans amd Online Privacy: The system is broke. Aneenberg Public Policy Center, University of Pennnsylvania. Retrieved October 21 2013 from: http://www.securitymanagement.com/archive/library/Anneberg_privacy1003.pdf
Wang, L. C., Baker, J., Wagner, J. A. & Wakefield K. (2007). Can a Retail Web Site Be Social? Journal of Marketing, July, 71(3), 143-157.
Wu, L.-L., Joung, Y.-J. & Chiang, T.-E. (2011). Recommendation Systems and Sales Concentration: The Moderating Effects of Consumers' Product Awareness and Acceptance to Recommendations. System Sciences (HICSS), 2011 44th Hawaii International Conference on. IEEE, pp. 1-10.